Modèle innovant d'apprentissage automatique pour la détection des fuites de données

Table des matières
CybelAngel est capable d'alerter sur un ensemble de plans sensibles parmi les milliers de milliards de documents disponibles sur le web. Vous êtes-vous déjà demandé comment nous y parvenons ? Laissez-nous vous présenter le dernier modèle d'apprentissage automatique pour la détection des fuites de données : l'évaluation du contenu. Nous associons l'apprentissage automatique de pointe à l'expertise humaine. Si rien ne remplacera les cyber-analystes, la technologie peut aider à réduire le bruit, à accélérer la détection des menaces réelles et à contextualiser la fuite pour faciliter l'enquête. Alors que CybelAngel déploie de nouvelles capacités de détection sur les serveurs de fichiers, nous avons considérablement amélioré nos algorithmes d'apprentissage automatique utilisés pour le filtrage et la contextualisation. En fin de compte, nos clients peuvent réagir plus rapidement aux fuites les plus critiques qui menacent leur entreprise.
Comment CybelAngel utilise l'apprentissage automatique pour détecter les fuites de données
Avant d'apparaître sur le Plate-forme CybelAngel DRPS sous la forme d'un rapport d'incident, un document détecté sur un serveur ouvert a traversé un entonnoir : 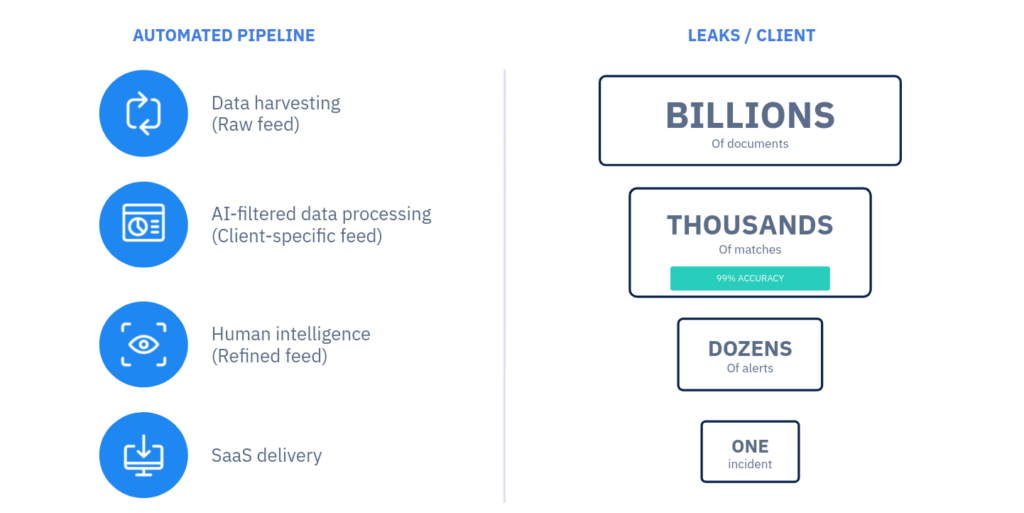 Chez CybelAngel, l'apprentissage automatique est utilisé pour deux objectifs principaux. Le premier objectif est de détecter automatiquement la gravité potentielle d'une fuite de documents sur un serveur ouvert, sur la base de métadonnées telles que les chemins d'accès aux fichiers. Cela permet à CybelAngel de scanner l'ensemble du web rapidement et efficacement. Nos algorithmes d'apprentissage automatique, formés sur des ensembles de données massives du monde réel, déterminent la probabilité que le serveur soit critique. Si cette probabilité dépasse un certain seuil, le serveur est transmis à des experts en cybersécurité pour analyse. Le deuxième objectif de l'apprentissage automatique est de détecter le contenu pertinent dans les documents. Il analyse le contexte sémantique autour des mots-clés correspondants pour s'assurer que les informations concernent véritablement nos clients. L'apprentissage automatique consiste à transformer des milliers de correspondances en dizaines d'alertes avant qu'elles ne soient transmises aux cyber-analystes pour un examen plus approfondi. Pour ce faire, nous construisons, formons et utilisons des systèmes d'apprentissage automatique. Modèles d'apprentissage automatique comme l'évaluation du contenu.
Chez CybelAngel, l'apprentissage automatique est utilisé pour deux objectifs principaux. Le premier objectif est de détecter automatiquement la gravité potentielle d'une fuite de documents sur un serveur ouvert, sur la base de métadonnées telles que les chemins d'accès aux fichiers. Cela permet à CybelAngel de scanner l'ensemble du web rapidement et efficacement. Nos algorithmes d'apprentissage automatique, formés sur des ensembles de données massives du monde réel, déterminent la probabilité que le serveur soit critique. Si cette probabilité dépasse un certain seuil, le serveur est transmis à des experts en cybersécurité pour analyse. Le deuxième objectif de l'apprentissage automatique est de détecter le contenu pertinent dans les documents. Il analyse le contexte sémantique autour des mots-clés correspondants pour s'assurer que les informations concernent véritablement nos clients. L'apprentissage automatique consiste à transformer des milliers de correspondances en dizaines d'alertes avant qu'elles ne soient transmises aux cyber-analystes pour un examen plus approfondi. Pour ce faire, nous construisons, formons et utilisons des systèmes d'apprentissage automatique. Modèles d'apprentissage automatique comme l'évaluation du contenu.
À propos de la Notation du contenu Modèle d'apprentissage automatique
Notation du contenu est un modèle d'apprentissage automatique propriétaire qui examine le contenu des documents détectés sur les serveurs de fichiers ouverts afin de déterminer s'il s'agit d'une menace réelle. Si c'est le cas, il attribue une note à l'alerte en fonction des critères expliqués ci-dessous. Notation du contenu fonctionne en combinaison avec d'autres modèles dans le pipeline d'apprentissage automatique, ajoutant une couche supplémentaire de filtrage et de contextualisation. Mise en œuvre Notation du contenu nous a permis de le faire :
- Réduire le bruit par 30% pour les analystes ;
- Envoyez des alertes critiques pour qu'elles soient examinées avant les autres ;
- Garantir l'absence de faux positifs ;
- Éviter les faux négatifs.
Lire aussi : RSSI : Faites de 2020 l'année où vous vous concentrerez sur le risque cybernétique des tiers
Comment les les Notation du contenu Modèle d'apprentissage automatique travail ?
Le Notation du contenu Le modèle d'apprentissage automatique s'appuie sur deux autres algorithmes qui opèrent directement sur le contexte textuel du fichier pour déterminer à la fois la catégorie et la sensibilité du fichier. Comme les autres modèles d'apprentissage automatique, il se compose des éléments suivants :
- Un classificateurqui vise à lire le contenu de l'alerte comme le ferait un être humain. Il prédit la criticité d'une détection en fonction de ce qu'il trouve dans les fichiers. Le classificateur attribue une note de 1 à 100 à la détection.
- Un seuil, qui est utilisé pour prendre des décisions sur la base du score généré par le classificateur.
En dessous d'un certain seuil, l'alerte est rejetée. Elle n'atteindra jamais le flux de l'analyste pour investigation. Voici un exemple de ce qui se passe dans le pipeline d'apprentissage automatique au cours d'une journée moyenne, pour un client moyen :
- 400 alertes pour des documents exposés sur des serveurs ouverts entrent dans le pipeline d'apprentissage automatique ;
- 100 de ces 400 seront analysés par l'équipe d'experts. Notation du contenu après 75% du flux initial sont rejetés parce que les métadonnées des fichiers ne sont pas pertinentes.
- Seules 70 alertes seront finalement transmises aux analystes pour enquête.
L'ensemble de ce processus se déroule en quelques minutes. Dans un monde où chaque seconde compte, notre modèle robuste d'apprentissage automatique donne aux clients une longueur d'avance dans la sécurisation des actifs exposés à leur insu.
