Google dorks for OSINT: how Security Teams use Search Operators for Open Source Intelligence

Inhaltsübersicht
Google indexes approximately 8.5 billion pages daily and has no mechanism to distinguish between information an organisation intended to publish and information that ended up public by accident. That gap is what makes Google one of the most powerful reconnaissance tools available to security teams in 2026, and one of the most consistently underestimated. Google dorking is a standard reconnaissance phase activity in penetration testing, a daily workflow tool in threat intelligence operations, and the fastest free method available for auditing internet-facing exposure. This guide covers how security teams actually use it in practice, not as a theoretical technique but as a structured operational workflow.
If you are looking for the full operator reference and cheat sheet, that is in the Google Dorks cheat sheet. If you want to understand the Google Hacking Database and how to navigate it, that is covered in the GHDB guide. This article covers the intelligence methodology: how experienced analysts build investigation workflows, which operator combinations produce the most useful results, and how Google dorking fits into a broader OSINT programme alongside Shodan, Censys and automated tools.
What Google dorking actually is, for practitioners
Google dorking, also called Google hacking, is the use of advanced search operators to force Google’s index to return highly specific results that a standard search would never surface. The technique was systematised by security researcher Johnny Long in the early 2000s and has evolved continuously since. As of 2026, Google supports 25 or more working operators with a further 12 or more deprecated, the loss of the Zwischenspeicher operator in 2024 was the most impactful for OSINT practitioners, as it was a cornerstone technique for viewing deleted or modified pages. The Wayback Machine is the closest replacement, though coverage is inconsistent.
What makes Google dorking valuable for security teams specifically is the combination of three properties. First, it is passive: every query goes to Google, not to the target, which means no traffic appears in the target’s access logs. Second, it scales: the same operator combinations that surface one exposed credential file will surface every exposed credential file indexed from a target domain. Third, it reveals unintentional exposure: the information Google dorks find was always technically public, but it was never intended to be discoverable. That distinction between technically public and practically accessible is the attack surface that OSINT exploits.
The five operator families that matter for security OSINT
Practitioners who use Google dorks professionally organise their workflows around five operator families, each targeting a different category of intelligence.
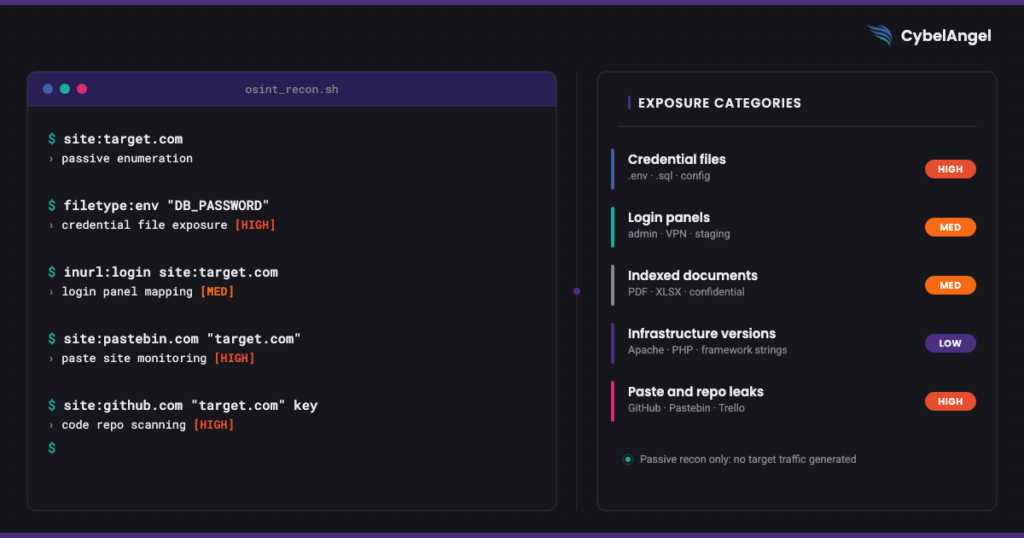
1. Scoping operators, define the investigation boundary
site:targetdomain.com, restricts all results to a specific domain or subdomain. The foundation of any organisation-specific investigation.site:targetdomain.com -www, removes the main site from results, surfacing subdomains and forgotten infrastructure.related:targetdomain.com, returns sites Google considers related, useful for mapping affiliated domains, subsidiaries and partners.link:targetdomain.com, partially deprecated but still returns some results for sites linking to the target, useful for mapping the organisation’s external relationships.
2. File and content operators, find what should not be indexed
filetype:pdf site:targetdomain.com, surfaces all indexed PDFs. Extend toxlsx,docx,sql,env,Protokoll,bak,confdepending on what category of exposure you are investigating.filetype:env "DB_PASSWORD" site:targetdomain.com, specifically targets environment files containing live database credentials. One of the highest-severity dork categories.intitle:"index of" site:targetdomain.com, finds web server directories with directory listing enabled. Open directories expose file structures, uploaded documents and configuration files.intext:"confidential" filetype:pdf site:targetdomain.com, combines content operator with file type to surface documents marked as confidential that are nonetheless publicly indexed.
3. Authentication surface operators, map login exposure
inurl:login site:targetdomain.com, surfaces all indexed login pages across the target’s web estate including forgotten staging environments and legacy applications.inurl:admin site:targetdomain.com, maps administrative interfaces that may lack adequate access controls.intitle:"VPN" OR intitle:"remote access" site:targetdomain.com, identifies remote access infrastructure that is internet-facing and potentially vulnerable.inurl:"/wp-admin" site:targetdomain.com, WordPress-specific admin panel enumeration, relevant for any organisation running WordPress as its CMS or for third-party sites hosted on the target domain.
4. Technology fingerprinting operators, identify the stack
intitle:"phpinfo()" site:targetdomain.com, finds PHP information pages that expose server version, configuration details and installed modules.intext:"Powered by" intext:"version" site:targetdomain.com, surfaces version strings that can be cross-referenced against the CVE database.intext:"Apache/2" site:targetdomain.com, identifies specific web server versions for vulnerability mapping.intitle:"Grafana" OR intitle:"Kibana" OR intitle:"Elasticsearch" site:targetdomain.com, targets commonly exposed monitoring and analytics platforms that frequently lack authentication when internet-facing.
5. Threat intelligence operators, monitor for data exposure
site:pastebin.com "targetdomain.com", monitors paste sites for mentions of the organisation’s domain, a common signal of credential dumps or data exfiltration.site:github.com "targetdomain.com" password OR secret OR key OR token, finds code repositories referencing the organisation that may contain exposed credentials or API keys.site:trello.com "targetdomain.com", surfaces public Trello boards referencing the organisation, a persistent source of inadvertent data exposure as documented in the Trello security guide."@targetdomain.com" site:linkedin.com, enumerates employee email addresses in a format that enables targeted phishing or credential stuffing validation.
How experienced analysts build investigation workflows
The difference between using Google dorks as a list of queries and using them as an OSINT methodology is workflow structure. Analysts who produce consistent, actionable results follow a pattern that mirrors the broader OSINT intelligence cycle: define the objective, scope the target, enumerate systematically, prioritise findings, act and report.
Phase 1, Objective definition
Before running a single query, define what you are investigating and what a finding would look like. Investigating credential exposure for a specific organisation produces different queries than investigating phishing infrastructure targeting your brand. Undefined objectives produce large volumes of irrelevant results and miss the specific exposure categories that matter.
Phase 2, Passive enumeration
Begin with broad scoping queries to map what is indexed: site:targetdomain.com gives you the total indexed page count. site:targetdomain.com -www surfaces subdomains. site:targetdomain.com filetype:pdf OR filetype:docx OR filetype:xlsx gives you the document footprint. This phase reveals the investigation surface before you start drilling into specific exposure categories.
Phase 3, Targeted drilling
Move from broad to specific using the operator families above. Work through file and content operators, authentication surface operators and technology fingerprinting operators systematically. Each category produces findings that inform the next: an exposed .env file reveals what cloud services the organisation uses, which then informs queries targeting those specific platforms.
Phase 4, Multi-engine cross-referencing
Google supports Seite: universally but analysts who treat dorking as a Google-only activity leave significant intelligence on the table. Bing accepts almost identical operators and sometimes indexes lower-authority domains that Google does not. Yandex provides different coverage particularly for Eastern European infrastructure. Shodan and Censys operate on device and certificate data rather than web content, making them essential complements for infrastructure mapping. A complete OSINT workflow combines Google for web content, Bing for supplementary coverage, and Shodan or Censys for exposed services and version identification.
Phase 5, Automation for scale
Manual Google dorking is limited by rate controls and CAPTCHA. For large-scale investigations or continuous monitoring, practitioners use tools including Pagodo (a Python tool that runs GHDB dorks at scale), theHarvester (which combines Google dorking with other data sources for email and subdomain enumeration), and recon-ng (a full-featured reconnaissance framework with Google Search modules). A recent development in 2024 to 2026 is LLM-based tools that generate dork variants from natural-language prompts, reducing the operator knowledge required and enabling analysts to describe what they are looking for in plain language and receive optimised queries in return.
The OSINT investigation patterns SecOps teams use most
These are the specific investigation patterns that appear most frequently in documented security OSINT workflows, drawn from practitioner community discussions, published threat intelligence methodologies and CybelAngel REACT team observations.
Brand and domain monitoring. A continuous monitoring workflow rather than a point-in-time audit. Runs a standard set of dorks against the organisation’s primary domain and known subsidiaries on a weekly cycle, looking for new exposed documents, new subdomains, new mentions on paste sites and new GitHub repositories referencing the domain. The objective is not to audit the current state once but to detect new exposures as they appear.
Phishing infrastructure detection. Uses inurl: und intitle: operators to find newly indexed pages impersonating the target organisation. intitle:"login" "targetbrand" -site:targetdomain.com finds pages that reference the brand name and contain login interfaces but are not on the legitimate domain, a signature pattern of phishing page infrastructure. Combines with site:pastebin.com "targetdomain.com" und site:github.com "targetdomain.com" for a broader threat surface view.
Third-party and supply chain investigation. Extends standard dorks to vendor domains and integration partners. If a target organisation uses ten named SaaS vendors, running exposure dorks against each vendor’s domain reveals whether any of them has indexed sensitive data that could be used to target the primary organisation. The Episource breach, which exposed 5.4 million patient records through a third-party billing vendor, began with exactly the kind of vendor-side exposure that this investigation pattern surfaces.
Executive and personnel OSINT. Combines site:linkedin.com enumeration with filetype searches for documents containing employee names, and paste site searches for email address patterns. Used in red team engagements to build the personnel map that informs spear phishing simulations, and in threat intelligence to assess whether executive personal information has been published on paste sites or dark web forums. Connects directly to the executive doxxing risk covered in the executive doxxing attack guide.
Vulnerability reconnaissance. Combines technology fingerprinting operators with CVE cross-referencing. Identify the version of an exposed application using intitle: oder im Text: operators, then check the identified version against the CVE database. The pattern is particularly valuable for finding exposed instances of recently disclosed vulnerabilities across large organisations with complex web estates where centralised patch status visibility is incomplete.
What Google dorking cannot do, and what fills the gaps
Google only indexes what its crawler can reach. Authentication-gated content, dark web infrastructure and platforms that block crawling are invisible to dork queries. The index is not real-time, as new content takes hours to days to appear, and deleted content persists long after the source is gone. Manual dorking is point-in-time in that it captures today, it misses the .env file pushed tomorrow.
CybelAngel’s Attack Surface Management platform runs this reconnaissance continuously. Why not find out what is indexed on your domain right now?
FAQs
Shodan and Censys index what is reachable at the network layer — open ports, service banners, TLS certificates, device fingerprints. Google indexes what its crawler can read at the application layer — documents, directory listings, error pages, configuration files, login interfaces and anything else that renders as HTML or a downloadable file. The gap between those two data sets is where Google dorking produces findings that neither tool surfaces: an .env file served by a misconfigured web root, a /backup directory with no authentication, a phpinfo() page exposing server internals. The workflows are complementary, not redundant. If you are only running one, you are missing a significant portion of the external attack surface.
Pre-exploitation reconnaissance, specifically the transition from passive to active. Dorking maps authentication surfaces before you touch them, identifies technology versions before you check exploit-db, and surfaces credential material before you attempt a single login. The specific finding that changes engagement outcomes most consistently is the exposed .env file — a single file containing APP_KEY, DB_PASSWORD, AWS_SECRET_ACCESS_KEY und STRIPE_SECRET simultaneously collapses what would otherwise be a multi-stage intrusion into a single Google query. In a well-scoped external penetration test, 30 to 45 minutes of structured dorking against a target domain reliably surfaces one or two findings that active scanning would have taken days to reach through the normal vulnerability enumeration path.
The query itself is not the legal exposure. Google’s crawler retrieved the content, indexed it, and is returning it in response to your search query — that is Google’s activity, not yours. The line is crossed at the point of direct interaction with the target system. Authenticating to a login panel you found through dorking without authorisation is unauthorised access regardless of how you found the panel. Downloading a database backup from an open directory constitutes unauthorised access to a computer in most CFAA readings even if the directory required no credentials, because the data was not intentionally made public. Credential stuffing against an exposed authentication surface using credentials found in a dorked paste is multiple overlapping statutes simultaneously. The practical test: if your activity generates server-side logs on the target, you have crossed from passive reconnaissance into active interaction.
Ranked by consistent severity across documented engagements: filetype:env intext:"DB_PASSWORD" OR intext:"AWS_SECRET" site:target.com produces the highest direct impact when it returns results — a live credential file is immediate critical severity. intitle:"index of" inurl:backup site:target.com surfaces database dumps and archive files that represent full data exposure. inurl:phpinfo.php site:target.com combined with the identified PHP version against a CVE lookup frequently produces a direct exploitation path with available public PoC. site:pastebin.com "target.com" password und site:github.com "target.com" token OR secret OR key are the highest-yield threat intelligence operators — they surface credential exposure that originated outside the target’s own infrastructure and that the target’s own security team has no visibility into.
Google aggressively rate-limits automated queries. Without the Custom Search JSON API, automated tools typically encounter CAPTCHAs after 10 to 20 rapid queries from the same IP. Pagodo handles this through configurable delays between queries — the default is a randomised sleep between 37 and 60 seconds per query, which is slow but reliable. The Custom Search JSON API provides 100 queries per day on the free tier and up to 10,000 queries per day on paid tiers, with a maximum of 10 results per query, which limits its utility for exhaustive enumeration. For large-scale continuous monitoring, external attack surface management platforms that maintain distributed crawling infrastructure and cached index data significantly outperform what any individual analyst can achieve through either manual queries or open-source tooling against Google’s rate limits.
Google’s indexing delay ranges from hours to weeks depending on the domain’s crawl priority and content type. For threat intelligence use cases where timing matters — monitoring for credential dumps, tracking phishing infrastructure, detecting newly indexed sensitive files — this lag is operationally significant. Three mitigations: first, use after: date filtering to surface recently indexed content and run queries on a scheduled cycle rather than ad hoc. Second, supplement with paste site APIs (Pastebin has a public scraping API, IntelligenceX and similar services index paste content in near real-time) for the highest time-sensitivity use cases. Third, treat Google dorking as a detection layer for persistent exposure rather than real-time alerting — it reliably surfaces what has been indexed, not what appeared in the last hour. For real-time credential and data leak detection, dedicated dark web monitoring and paste site alerting services operate on significantly shorter detection timelines than any Google-based approach can achieve.
Über den Autor

