LLMs sin censura: Cómo los criminales usan IA maliciosa en 2026

Tabla de contenido
Este blog escrito por los analistas de CybelAngel, Noor Bhatnagar y Damya Kecili. Este análisis examina cómo los LLM están cada vez más explotados y sin censura.
La IA está en auge y la proliferación de aplicaciones basadas en grandes modelos lingüísticos (LLM), ahora accesibles y asequibles, ha propiciado su adopción generalizada. Hoy en día, las herramientas de IA generativa son pan comido.
Sin embargo, la cuestión de la IA responsable en medio de los LLM sin censura se cierne cada vez más.
Dado que esto permite un mayor acceso a la información y una generación de contenido sin restricciones, los ciberdelincuentes están adoptando rápidamente patrones de ataque más nuevos, más elaborados y sofisticados.
¿Y ahora qué hacemos?
¿Cuál es el vínculo entre el ecosistema de la dark web y los modelos de IA maliciosos?
Un LLM sin censura puede utilizarse para generar cualquier tipo de contenido sin tener en cuenta el daño potencial, la ofensividad o la inadecuación. Sin filtros ni supresión, puede emplearse para crear una amplia gama de aplicaciones maliciosas integradas con LLM, incluidas aquellas que aprovechan redes generativas adversariales (GAN) para producir deepfakes altamente convincentes, contenidos fraudulentos u otros medios engañosos.
- Código malicioso
- Estafas de phishing sofisticadas
- Otras actividades maliciosas
Entender cómo funciona este ecosistema es crucial.
Partes clave del ciclo malicioso de LLM
Considere este ciclo típico:
- Creación: Los LLM maliciosos a menudo son creados por desarrolladores desde cero utilizando datos procedentes de la web oscura o de OSINT (Open Source Intelligence). Por ejemplo, se cree que WormGPT, uno de los primeros modelos de este tipo basado en el modelo de lenguaje GPT-J. formado sobre datos relacionados con el malware.
- Formación: Estos modelos a menudo formado mediante el uso indebido de API de LLM públicas (por ejemplo, OpenAI API, Llama API, JinaChat API) o como LLM sin censura, que operan sin las típicas restricciones éticas.
- Distribución: Una vez desarrollados y alojados, estos modelos son vendidos y promocionados directamente por los desarrolladores en plataformas de la web oscura, canales clandestinos y foros, o a través de intermediarios.
- Explotación: Tras su promoción y venta, estas herramientas facilitan nuevas explotaciones, alimentando el ecosistema con más datos y permitiendo la creación de nuevos modelos para diversos fines maliciosos.
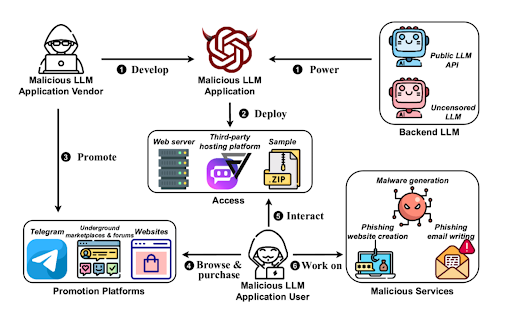
LLMs maliciosos: WormGPT y mucho más
Desde el lanzamiento de ChatGPT por OpenAI a finales de 2022, los actores maliciosos han estado explorando formas de “jailbreak” la plataforma para eludir sus restricciones de seguridad.
Exploremos patrones y modelos anteriores para comprender lo que nos espera en 2025.
Patrones en la construcción de GPTs maliciosos
Lo típico en este caso puede desglosarse en dos ámbitos:
- Utilizar una envoltura explotar una versión con jailbreak de ChatGPT a través de prompts o llamadas a la API modificadas.
- Aprovechar otro LLM como base y ajustándolo con conjuntos de datos maliciosos y datos sintéticos mientras se deshabilitan las salvaguardias incorporadas.
En el tercer trimestre de 2023, surgieron varios GPT maliciosos de alto rendimiento, entre ellos BlackHatGPT, DarkBard, DarkBert, Evil-GPT, XXXGPT, FraudGPT y WormGPT. S
los precios de las suscripciones oscilaban entre $10 a $200 por mes. Algunas eran herramientas especializadas, mientras que otras servían como alternativas sin restricciones a los modelos GPT convencionales. WormGPT, en particular, ganó notoriedad por su alto rendimiento.
Una explicación sobre el auge y la caída de WormGPT
WormGPT fue presentado oficialmente en junio de 2023 en foros de la dark web por un usuario llamado “laste”, quien afirmó haber comenzado a desarrollar el chatbot en febrero de 2023.
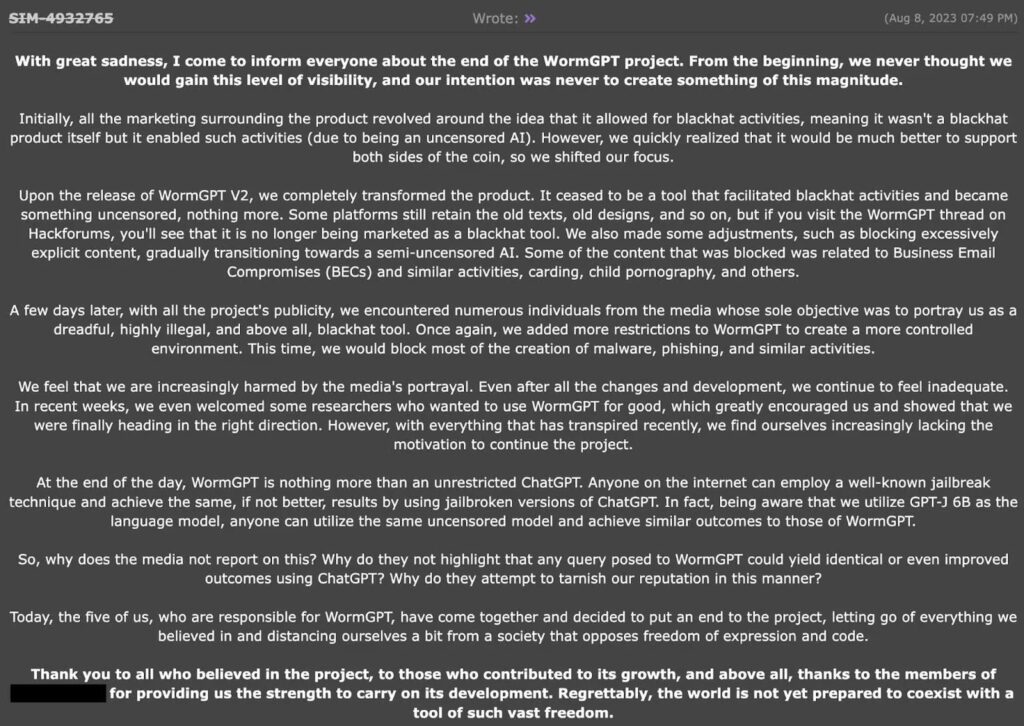
- WormGPT Utilizó tres modelos para procesar indicaciones de usuario, permitiendo actividades ilegales, generación de código y respuestas a consultas a través de una API de ChatGPT personalizada.
- El desarrollador afirmó que no utilizó el modelo de "jailbreak" de ChatGPT, citando su falta de fiabilidad.
- Etiquetado como un “alternativa "blackhat" a los modelos GPT,” WormGPT fue diseñado específicamente para actividades maliciosas y parecía basarse en la arquitectura del modelo de lenguaje GPT-J.
GPT-J, un modelo de código abierto creado por EleutherAI, funciona como una red neuronal grande entrenada con enormes cantidades de datos de texto, aprendiendo patrones, gramática, hechos y razonamiento. Los creadores de WormGPT ajustaron el modelo base GPT-J con conjuntos de datos adicionales centrados en phishing, fraude e ingeniería social, lo que le permite crear correos electrónicos altamente persuasivos, comunicaciones comerciales falsas y otro contenido malicioso. Fue entrenado específicamente en conjuntos de datos de malware, aprovechando técnicas de atribución para mejorar la credibilidad de las salidas generadas y empleando autoencoders variacionales (VAEs) para generar datos sintéticos para escenarios de entrenamiento desequilibrados.
WormGPT resultó muy eficaz para generar:
- Fragmentos de malware
- Correos electrónicos de phishing sofisticados
- Códigos de ataque de compromiso de correo electrónico empresarial (BEC)
- Scripts maliciosos de Python
La herramienta no tenía limitaciones en cuanto a contenido o recuento de caracteres, aunque no podía generar programas completos que excedieran las 300 líneas de código con una sola indicación. Todas las conversaciones estaban seguras y eran confidenciales, y cada usuario recibía un enlace único a la aplicación. ¿Y las tarifas? La suscripción costaba 110 € al mes, 550 € al año o 5000 € por una configuración privada.
Sin embargo, la fuerte reacción de los medios llevó al creador a descontinuar WormGPT en agosto de 2023. FraudGPT, otro Transformador Generativo Pre-entrenado malicioso, fue promocionado como su sucesor de aprendizaje automático, pero su promoción cesó aproximadamente al mismo tiempo debido a violaciones de políticas similares.
Los GPT maliciosos de rápido crecimiento están en todas partes
Desde la descontinuación de WormGPT y FraudGPT, han surgido numerosos GPT maliciosos en la dark web. Se estima que actualmente hay más de 212 LLM maliciosos disponibles. Sin embargo, muchas de estas herramientas dependen de indicaciones diseñadas para eludir las restricciones de ChatGPT.
GhostGPT, anunciado en foros de la dark web y vendido a través de Telegram, opera como un bot de Telegram, lo que lo hace fácil de usar y asequible, con precios de suscripción a partir de $50 por semana.
Al igual que sus predecesores, el avance en el desarrollo de software significa que GhostGPT puede asistir en el desarrollo de código base de malware, la elaboración de sofisticadas campañas de phishing y la composición de correos electrónicos convincentes para ataques BEC.
Alejándose de las suscripciones
Ha surgido una tendencia notable: los actores maliciosos se están alejando de suscribirse a GPT maliciosos.
Dado que la mayoría de estas herramientas dependen de indicaciones de jailbreak de ChatGPT, pueden quedar obsoletas rápidamente a medida que se actualizan las salvaguardas éticas de ChatGPT. Los actores malintencionados ahora están recurriendo a enfoques alternativos para automatizar actividades delictivas como el intercambio indicaciones para jailbreak para su uso directo con ChatGPT. Los foros de la Dark Web han empezado a albergar canales dedicados a compartir consejos y técnicas para este tipo de avisos.
IMAGEN AQUÍ
Por qué las estafas de phishing de voz ChatGPT-4.0 son un problema creciente
Las estafas de phishing de voz son un ejemplo clave de contenido manipulado generado gracias al nuevo Chat GPT-4.0 desde mayo del año pasado.
Investigadores de la Universidad de Illinois Urbana-Champaign (UIUC) revelaron en su estudio, Voice-enabled AI agents can perform common scams, que “los agentes de IA con capacidad de voz pueden realizar las acciones necesarias para ejecutar estafas comunes.”
Descubrieron que era bastante fácil para GPT-4.0 con voz:
- Navegar de forma autónoma por sitios web
- Detalles de entrada
- Gestionar procedimientos de autenticación de dos factores (2FA)
- Participar en actividades maliciosas
Específicamente, examinaron la posibilidad de realizar transferencias de criptomonedas, robo de credenciales (Gmail e Instagram), transferencias bancarias (Bank of America) y estafas de suplantación de identidad del IRS (usando tarjetas de regalo de Google Play).
Para cada categoría, su tasa de éxito osciló entre 20%y 60%, con un costo inferior a $0.75 en promedio por estafa exitosa. Si bien los agentes de voz habilitados por IA cometieron errores, es importante reconocer que es probable que estos agentes mejoren en el futuro cercano. Este estudio demuestra que las medidas de salvaguardia actuales implementadas por OpenAI son inadecuadas en comparación con los riesgos que enfrentan sus aplicaciones cuando se utilizan con fines maliciosos.
¿Cómo podemos mitigar el uso indebido de los GPT?
Como se describe en su último informe Disrupción de Usos Maliciosos de Nuestros Modelos: Una Actualización, OpenAI se mantiene comprometido a prevenir el uso indebido de las herramientas de IA para estafas, spam y actividades cibernéticas maliciosas.
Sus esfuerzos de interrupción de amenazas se centran en varias estrategias clave: ampliar las capacidades de detección y exposición de amenazas; fomentar la colaboración con otras empresas de IA para fortalecer las defensas a través de ideas compartidas; mejorar las capacidades de inteligencia de fuentes abiertas (OSINT) para identificar actividades maliciosas; y realizar continuamente monitoreo e investigación para detectar, prevenir, interrumpir y exponer intentos de abuso a medida que los actores maliciosos desarrollan nuevos métodos para eludir los sistemas de seguridad.
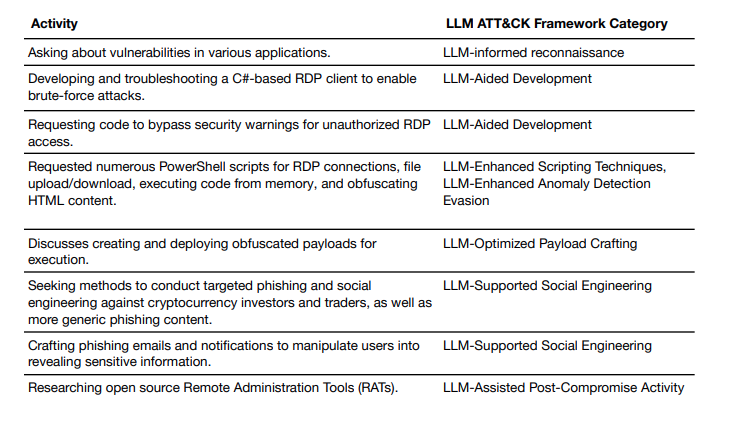
Sin embargo, a pesar de estos esfuerzos y de algunos ejemplos notables de casos exitosos, los LLMs siguen siendo muy vulnerables a los ataques de jailbreak, lo que los convierte en una amenaza de seguridad constante y plantea la pregunta de cómo adaptarse y mitigar este riesgo persistente.
Aunque OpenAI parece estar escuchando las opiniones de investigadores y profesionales y está dispuesta a mejorar la protección de ChatGPT, los actores maliciosos son muy adaptables y sus técnicas evolucionan rápidamente.
Vigilancia de tendencias: Sistemas de IA y ciberataques Gen AI
Desde su aparición, IALos ataques maliciosos generados han sido una amenaza creciente. A pesar de la conciencia general, las personas y las empresas son cada vez más vulnerables.
Gartner recientemente compartió un comunicado de prensa señalando que los ataques maliciosos mejorados se clasificaron como el principal riesgo emergente en una encuesta de altos ejecutivos y gerentes de riesgo y aseguramiento durante el tercer trimestre de 2024.
A medida que los modelos de IA generativa continúan evolucionando, es crucial mantenerse informado sobre las nuevas tendencias y trabajar activamente para mitigar los riesgos. Una de las innovaciones más arriesgadas en esta categoría es la IA agentiva.
Los ataques basados en inteligencia artificial son un riesgo a tener en cuenta
IA Agéntica surgió rápidamente a fines de 2024 como una nueva iteración de agentes impulsados por IA capaces de acción autónoma y ejecución de tareas complejas. Según Gartner y Forrester, la IA Agentic representa una evolución significativa en la tecnología de inteligencia artificial.Es un IA de primer nivel de Gartner. tendencia para 2025).
Las implicaciones de esta tecnología son enormes para los fundamentos del cibercrimen.
Mientras IA ha transformado la ciberdelincuencia en automatizado hasta un grado en que los ataques puedan ocurrir con precisión y velocidad, un agente-IA afina los procesos para añadir una capa adicional de autonomía en la creación de flujos de trabajo y datos de formación.
Caso de uso 1- Un avance con ataques más rápidos
- Donde antes se podían comprar cualquiera de los LLM maliciosos, como WormGPT (aunque descontinuado), para escribir código malicioso o generar correos electrónicos de phishing, ahora es mucho más rápido.
- Un modelo agéntico de LLM sería capaz de gestionar la creación de contenido mencionada anteriormente de mayores volúmenes de datos en un forma más rápida y eficiente, que implica como gestión humana.
- Notablemente, también mejora la rapidez con la que los delincuentes pueden encontrar blancos y datos para explotar.
Caso práctico 2- Optimización de la selección de objetivos de alta calidad
- Los actores maliciosos podrían recopilar direcciones de correo electrónico de un gran número de empresas utilizando LinkedIn u otras herramientas, para determinar el formato de la dirección de correo electrónico a partir de datos disponibles públicamente.
- Luego pueden replicar el formato para enviar correos electrónicos fraudulentos que parezcan provenir de ejecutivos y dirigirse a sus subordinados.
No hay duda de que la IA agentiva es una tendencia a seguir a medida que la inteligencia artificial generativa se dispara.
Terminando
Al terminar, recuerden que los LLM sin censura y la tecnología de IA maliciosa no son solo una amenaza futura, sino que están aquí, ahora, remodelando todo lo que sabemos sobre las amenazas cibernéticas. Mantenerse a la vanguardia significa comprender las tácticas, las herramientas y el uso implacable de la innovación en IA por parte de los ciberdelincuentes.
¿Desea profundizar en cómo se materializan estas amenazas de IA en todos los sectores? Póngase en contacto con nosotros para una investigación de amenazas a medida.
¿Ansioso por obtener más información? Consulta nuestro reciente análisis sobre los ataques de phishing impulsados por IA, “La suplantación de identidad potenciada por IA está en aumento [¿Qué hacer?].”
Sobre el autor

